“Specialized enterprise users” and accessibility
During a discussion of accessibility and the level of attention a company ought to pay to it, someone said
I have always worked in complex enterprise software where the user is a specialized individual and not the general public so accessibility has never been stressed or pushed beyond considering the impact of colors and contrast.
I seek only to take down what they said, so I’ll not name them here.
This position is entirely understandable, and I suspect that most designers working in a B2B environment receive this excuse from their organizations when asking about those organizations’ lack of attention to accessibility. Though it is understandable is also wrong-headed; a close reading reveals where.
“not the general public”
Note that
- many of the impairments that make poor attention to accessibility a problem are not any less prevalent in enterprises than in the general population, and
- where there are differences in prevalence (for example, there are far fewer blind people in knowledge work jobs than in the general population) it’s due in part to lack of attention to accessibility in the tools used or the jobs themselves, making it hard for those people to take jobs that rely on those tools.
In essence, companies discriminate against their employees and potential employees by not providing accessible tools, and companies that provide such tools but ignore accessibility are complicit, perhaps even participatory, in that harmful practice.
“specialized individual”
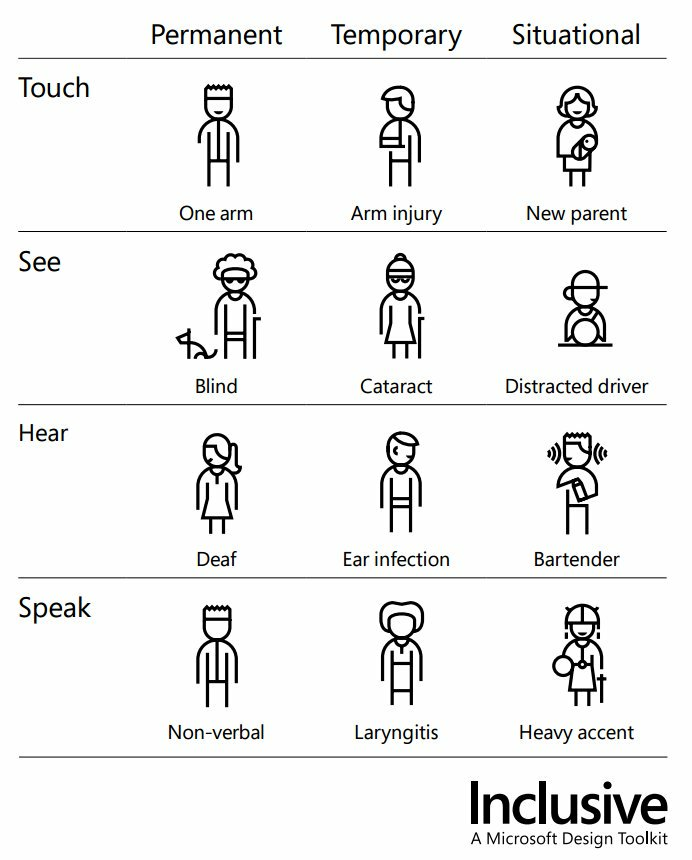
“Specialized” does not mean “without impairment.” Just as it is wrong to assume that an unnamed doctor is a man, it is wrong to assume that a librarian won’t have difficulty carrying books or a software developer won’t have difficulty typing or reading a screen. But even folks without long-term disabilities may have, situationally or temporarily, impairments where they too would benefit from attention to accessibility and inclusive design. Witness the very nice graphic from the Microsoft Inclusive Design Manual that demonstrates that people may need accommodation for a permanent issue, due to temporary illness or injury, or due to seemingly unrelated life circumstances. Inclusive design helps all of these.
{kind=link}
In this case, I’m not sure “specialized” is correct, even; typically, enterprise software is used by normal people with a normal level of specialness. We’re not dealing with thousands and thousands of Top Gun pilots here. The one way in which these users differ reliably from the general population is in domain knowledge relevant to their work, and even that domain knowledge is not evenly distributed. For example, I work with several systems in my job, and my level of expertise in each of them and the domain they operate in varies widely. I’m just not that special or specialized except in re a few of the many tools I use.
And don’t forget
Many of the interventions we’d entertain to improve accessibility also improve usability for all users. So the sadly common thought that folks with impairments are special cases that require extraordinary effort for little return is also incorrect.